Imputation
An interactive tutorial
In this chapter, you’ll learn how to handle NaN values in your dataset. You’ll learn a method to “fill in the blanks” called iterative imputation. But you’ll also learn the dangers of imputation, and some simple alternatives to imputation including listwise deletion and feature deletion.
Your job at Congo.com is to keep the package delivery workers happy. When they get stressed, more packages get damaged and lost. Here’s one worker’s stress levels during a week in July, as measured by her smartwatch:

Yes, and it’s a big problem! We can’t make decisions to lower stress if we don’t know what workers’ stress levels are. You can see the missing values in the raw data:
In the second row, NaN stands for “Not a Number”. A normal person would write “N/A”.
Datasets can have missing rows (due to sampling), missing columns (due to not measuring everything), and missing cells — that’s what a NaN value is.
But before we even try to handle NaN values, there are more ways for values to be “missing”! Look at the four other stress values listed above. Does one of them stand out as suspicious?
No, that looks reasonable. The stress values are between 0 and 100, so the odd one out is -1.
Yeah, there are a bunch of these strange -1 values, despite the stress values ranging between 0 and 100.
-1 actually means something like “sensor unreadable”. What should we do with those values?
Yeah, interpreting -1 as a real stress value could mess up our analysis — e.g. “What was their minimum stress value this week?” would return -1, which seems unreasonable.
I wouldn’t do that. Imagine you do some analysis on this data — say, “What was their minimum stress value this week?” If we leave these -1 values in, we’d get the answer -1. I don’t think that’s a sensible answer.
I think a more reasonable approach is to replace it with NaN, meaning “missing value”.
This dataset also contains strange -2 values. Suppose -2 means: “Too high to even display! Off the charts!” Then what could we do with those values?
I wouldn’t do that, for the same reason: it’s not a true stress value.
I think either NaN or 100 is reasonable. This “off the charts” error is an example of what statisticians call censoring. It tells us something about the value, but it’s not an exact reading. We could replace it with a large stress value, but for this chapter, we’ll play it safe and replace it with NaN.
Imputation: prediction or sampling?
Our task in this chapter is to somehow deal with those NaNs. A common approach is to “fill in the blanks” with guesses. This is called imputation. (This strange word rhymes with “computation”.)
Here are two possible ways we could impute the missing values. This first method uses mean-fill, which replaces every NaN with 23.1, the mean of the known values:

This second one uses norm-fill, which fits a normal distribution to the known values, then replaces every NaN with a random sample:

Which method do you prefer?
Okay! There’s no right or wrong answer here. But here are some ways to consider which is better.
Imagine you were given both stress timeseries above, and told that one of them was real, and one was fake. Which seems more likely to be “real”?
Yeah, those perfectly flat lines in the mean-fill would look very suspicious!
Those perfectly flat lines?! No, that would look very suspicious to me! You rarely see that in real-world data, especially in messy health statistics. I think the norm-fill looks more believable.
This is the idea behind one philosophy, which says that imputation is sampling. That is, we try to infer the distribution of possible true values, and randomly pick one as your imputation. So if we believe that stress comes from a normal distribution, the norm-fill method is better.
But here’s a different question. Imagine you had to bet on each missing value, and you were rewarded by how close your guess is. Which imputation would earn you the most money?
No, the mean-fill will actually earn you more. We’ll see why that is in a minute.
Yes! And in a minute, we’ll see why that is.
This is the idea behind the second philosophy, which says that imputation is prediction. That is, we again try to infer the distribution of the possible true values, but then we fill in the blanks with expected values. So if we imagine that stress comes from a normal distribution, it’s better to just impute with the mean every time. The norm-fill, by adding random deviations, just makes your prediction worse.
I think it depends on what you’re doing with your data. Your manager at Congo.com has said your task is to predict workers’ stress, so let’s run with the view that imputation is prediction. In a few minutes, you’ll see a contextual example of where sampling might make more sense.
Why are these values missing?
So far, our best solution to the missing stress values is to fill them all in with the observed mean, 23.1. Can we improve on that method?
For example, why not fill them in with some other constant value? Say, 50?
This suggestion might seem stupid, until we realize we’ve made an important assumption: that the observed values are representative of the missing values. That might not be true!
We need to ask: why are these values missing? Here are three possible theories.
Theory 1: whenever the worker is feeling too stressed, she takes off her watch. How would this affect your belief about our estimate, 23.1?
No, this theory should make us suspect that 23.1 is too low. The theory suggests that a stress value being missing is caused by the true stress value being high. So all those missing values are likely to have been higher than average, bringing up the mean.
Yeah. If missingness is caused by the true value being high, then all those missing values were probably higher than average, bringing up the mean.
Now for Theory 2: whenever the watch measures a stress value below 10, it reports NaN instead of the measurement. How would this affect your belief about our estimate, 23.1?
Right, it’s the inverse: if missingness is caused by the true stress value being low, then the true mean is probably lower.
No, this should make us think our estimate is too high. The theory suggests that missingness is caused by the true stress value being low. So all those missing values are likely to have been lower than average, bringing down the mean.
Theory 3: sensor failures happen when a Plutonium-238 atom decays in the smartwatch’s battery. How does this affect your belief about our estimate, 23.1?
Yes, in this case our estimate is just right. (Although if your stress is resulting in increased radioactivity, please call a doctor.)
Well, it’s widely agreed that atomic decay is a random event. (If your stress is resulting in radioactivity, call a doctor.) This means the measurements we are able to see are a fully random sample of the true values.
As you can see, the ideal imputation depends on why the data is missing.
When we decided to use mean-fill, we made an implicit assumption: the missing values are Missing Completely At Random (MCAR). But in the real world, your data is usually Missing Not At Random (MNAR), as in Theories 1 and 2. So mean-fill is probably going to bias our dataset.
A test set
So far, we just have thorny questions with no answers. And in general, that’s all you’ll have: no way to know why the values are missing, or what the “best” imputation method is.
But fortunately, you’re able to investigate. You hire a sports analyst to monitor the worker’s vitals for another three days, and you get this report back:

If we assume that this is a representative test set, then we can use it to answer some of our earlier questions. For example, here’s how mean-fill performs on this test set:

The true measurements are solid purple, and the predictions are outlined purple. The gray lines show the error for each measurement.
Eyeball it: does the mean 23.1 work well for this test set?
Yeah, the mean in the test set is 23.9, which is pretty close to our guess.
It’s not perfect, but I would say it works reasonably well. The mean in the test set is 23.9, which is pretty close to our guess.
This suggests (but certainly doesn’t prove!) that the stress data is Missing Completely At Random.
We can also use this test set to see how norm-fill compares to mean-fill, when viewing this as a prediction task. Below is the test set again, with the predictions being one norm-fill sample:

Which one, on average, has the smaller error lines?
Right — and here’s how we can quantify that.
I grant that it’s hard to eyeball this one! It’s actually mean-fill. We can quantify that as follows.
To measure our prediction quality, we’ll use mean squared error (MSE). We take the errors for each known value, square them, then take the mean. Mean-fill’s error is 400, but norm-fill’s error is 971.
Using more features to improve prediction
So after checking our methods and theories with a test set, our best method is still to impute with the mean, 23.1. Can we do better?
To improve our prediction, what’s the data scientist’s knee-jerk response?
Alright, let’s try that. Luckily, we have two other timeseries that might help: the worker’s heart rate and movement. Here’s the full “training set” for that week in July:
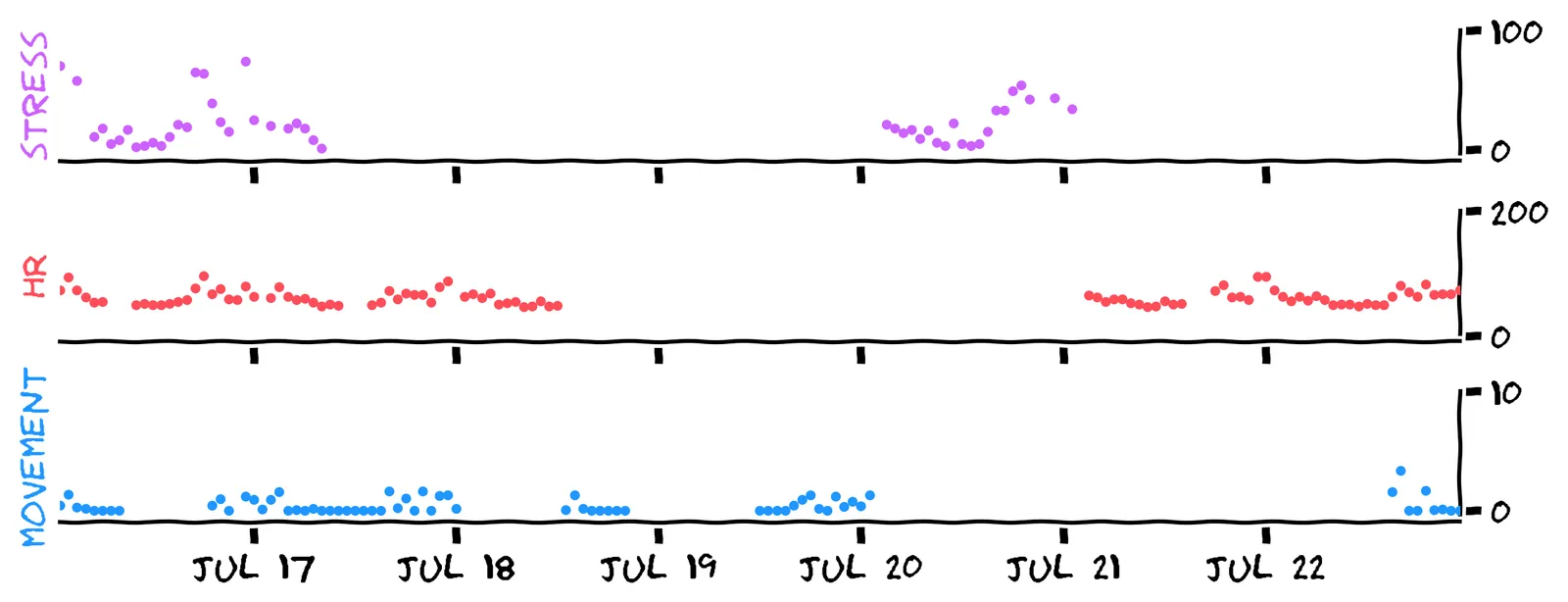
Welcome to the real world! It seems different sensors were working at different times. But it tells us something about the relationship between these variables, and we know something about most data points, so maybe we can solve this like a sudoku ...
Now, to do any prediction task, we need to choose a model. The first thing we’ll do is discard the “date” field of the dataset, and view the timeseries as a scatter plot:
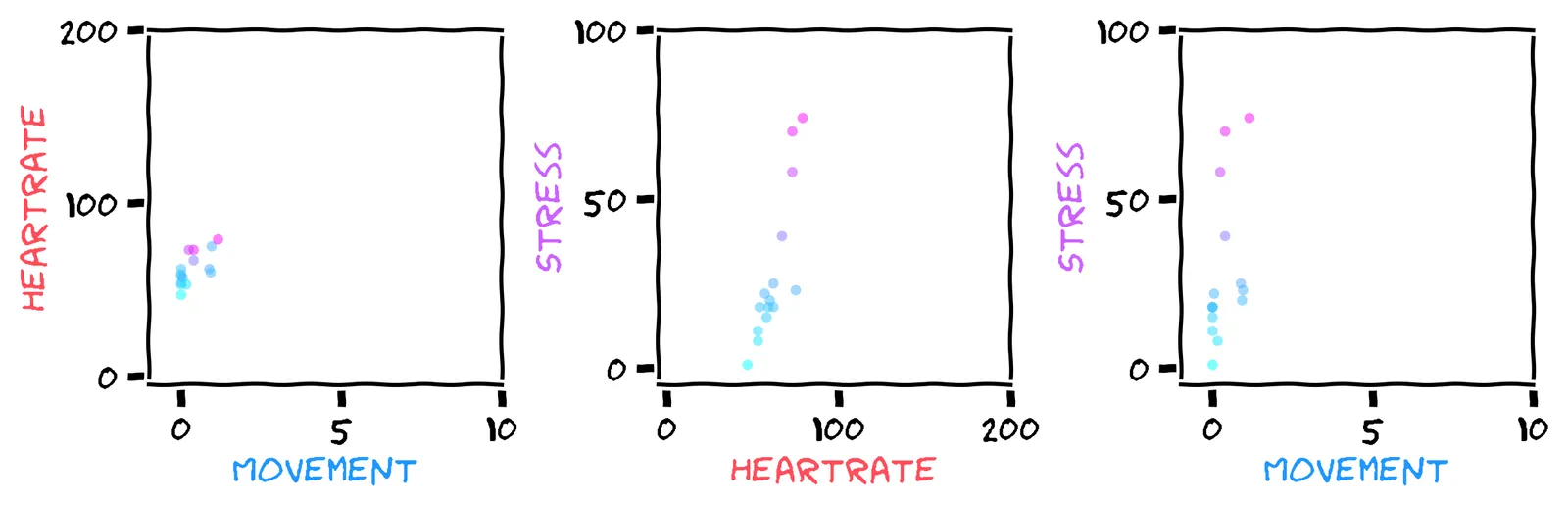
We can now view the dataset as points in a 3D cube. We show three scatter-plots, which are different views of the cube. You can imagine the first plot as a top-down view, and the second and third plots as “side-on” views. A point’s color is its stress level (where pink is high).
Looking at the scatter plots, which feature do you think is more useful for predicting stress?
Hmm, the middle chart looks more promising to me. I could draw a straight line through those points. But the relationship between movement and stress seems less clear.
Yeah, the middle chart suggests a fairly linear relationship between heart rate and stress. The relationship between movement and stress seems less clear.
We now need a model to fit to these data points. The scatter plot suggests that linear regression could work well. Linear regression works by trying to draw a straight line (or plane) through all the points.
When we run linear regression, it performs much better than constant mean, with an error of just 42:

Listwise deletion
Here’s a reason to suspect we can do even better. We started this chapter with 54 datapoints about stress. We then added more data: the heart rate and movement features. How many datapoints are used in the scatter plot?
Right, there are just 15 data points in the scatter plot!
No, there are actually just 15 data points in the scatter plot!
The thing is, scatter plots (and thus linear regression) can’t handle missing values. There’s no sensible way to plot a data point with a NaN value, and so all of these points are discarded entirely:
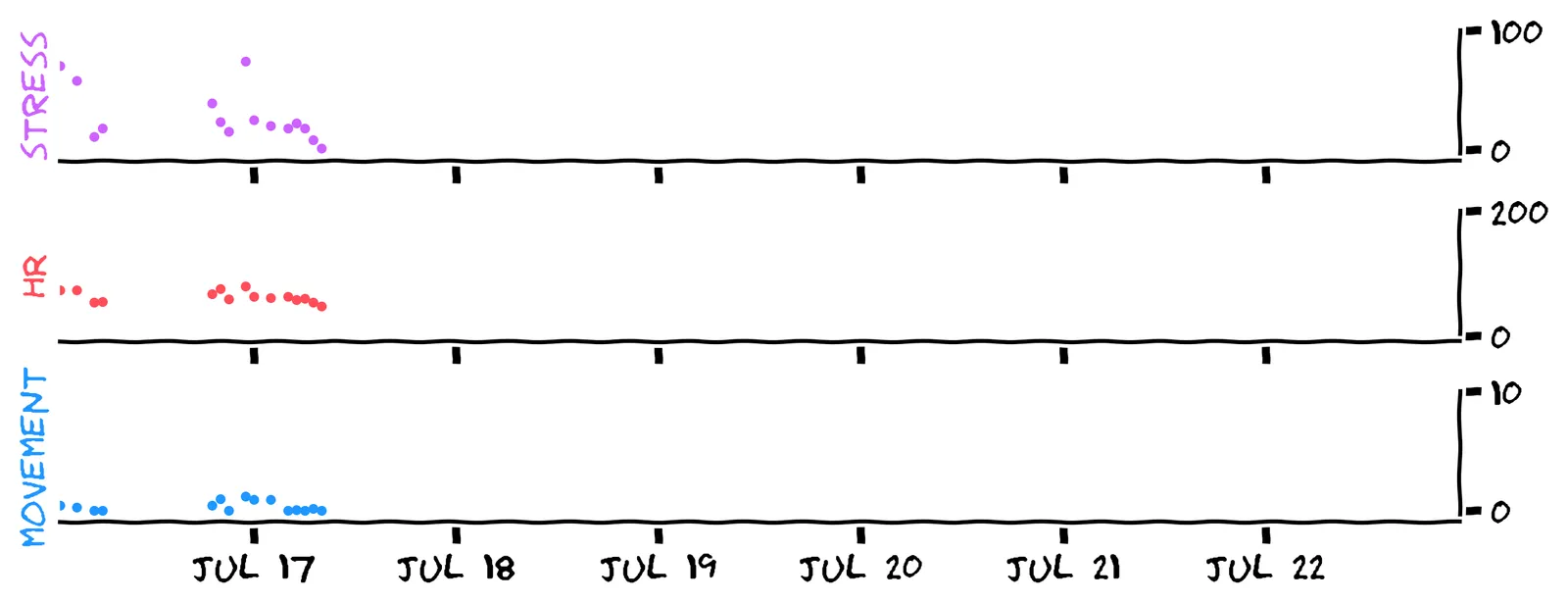
This approach is called listwise deletion. It results in a trade-off between the number of features and the number of data points. Imagine a dataset with 10 features, and 10% missing values. If you apply listwise deletion, what’s the least number of data points you could end up with?
Right — for example, all the missing values could be in the 10th feature, meaning every data point must be discarded.
No, in the worst case it can actually delete all of your data points! For example, all the missing values could be in the 10th feature. Then every data point has a NaN at feature 10, and must be discarded.
So here’s why we think we could do better: linear regression throws away most of our data set. Can we improve it by finding a way to plot those partial data points?
Imputing all features
Here’s an idea: let’s impute the movement and heart rate data too! That should help us keep those partial data points, and make every value in the training set available to help prediction.
Here’s what we get by using mean-fill on all three features:
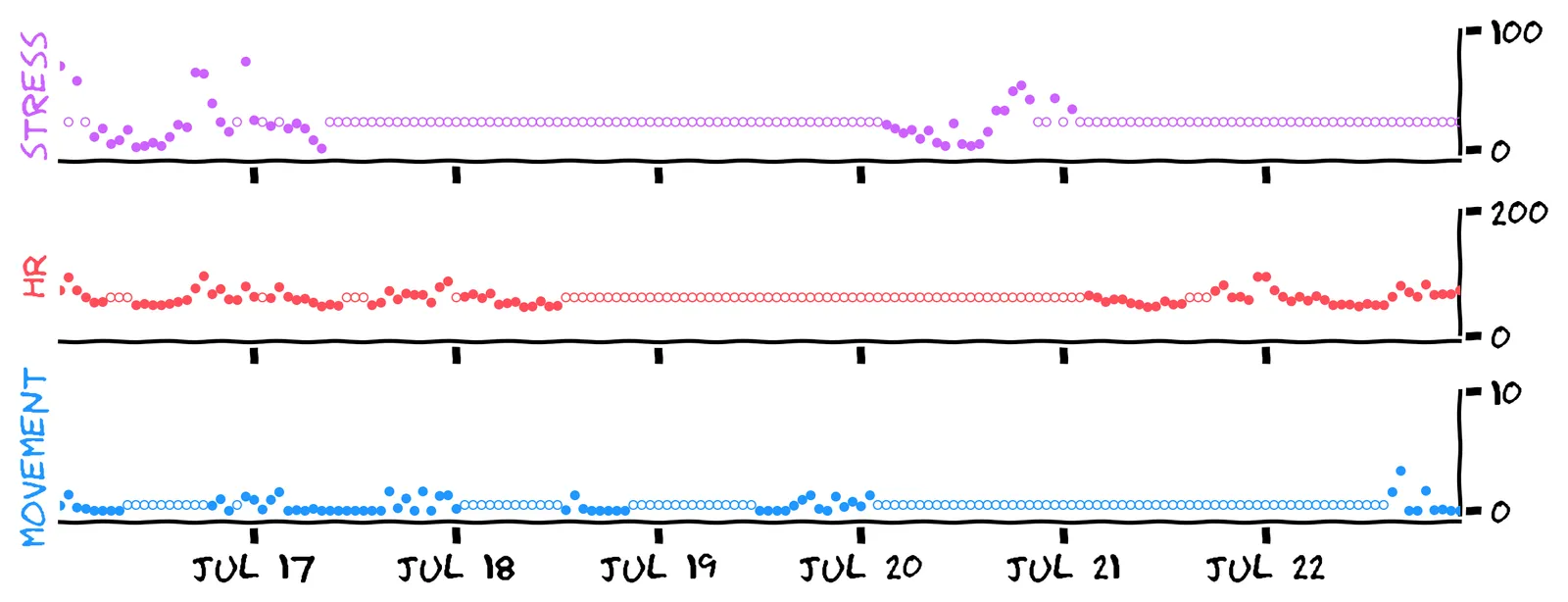
Now we can linear regression on the full training set, without throwing anything away! Have a guess — do you think it will perform better or worse than listwise deletion?
You must have good intuition!
That’s a very natural guess, but it actually performs worse!
We run linear regression on the mean-filled dataset. Then we use the test set again (which includes heart rate and movement data for prediction). We get this prediction:

The error is back up to 252! It’s only slightly better than mean-fill. Somehow, imputation has made things worse!
The clues are in the scatter plots:
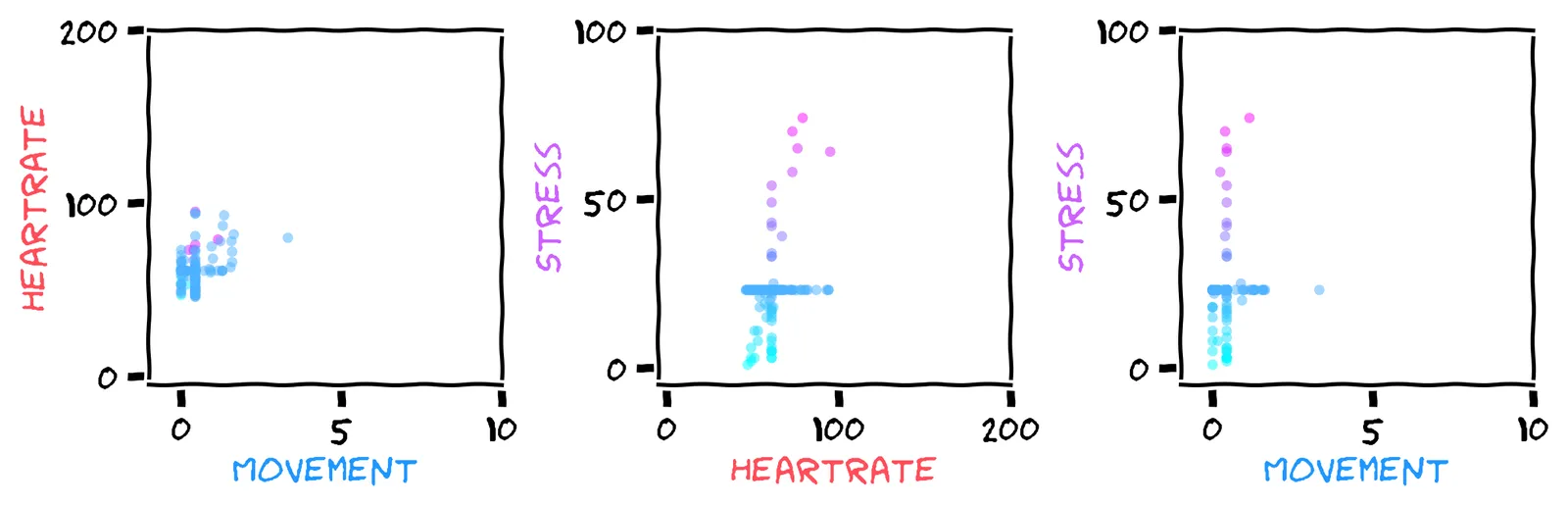
There are more data points in the scatter plot now, which is great! But now look at that middle plot. How has imputation affected the correlation between heart rate and stress?
I think it’s less clear! It was previously a nice straight line. The plot is now a mess, with an additional horizontal stripe and vertical stripe.
Indeed, what was previously a nice straight line is now a mess. Every plot has one long horizontal stripe and one long vertical stripe.
Perhaps using mean-fill on each feature is too naive? And indeed, there are many more sophisticated ways to impute a feature, like “join the dots”, or advanced timeseries analysis (like we did in the previous chapter).
But all these methods carry the same problem: if we impute each feature separately, we ignore the relationships between features.
Iterative imputation
So here’s where we’re at. Our best method to predict stress is still just to listwise-delete, then use linear regression. Imputation, despite making every measurement in the training set available, has only made things worse. This is because it destroys the relationships between features.
But ... perhaps our imputation method is not advanced enough? Can we impute each feature in a way that respects the relationships between features? One way is called iterative imputation.
Iterative imputation starts by imputing each feature separately with mean-fill, just like we’ve already done. But then it iteratively tries to replace those naive imputations with better ones.
First, it uses the imputed heart rate and movement features to predict stress, and replaces the naive stress imputations with those predictions.
Then it uses the imputed stress and movement features to predict heart rate, and replaces the naive heart rate imputations with those predictions.
Then ... do you see where this is going? What does it predict next?
No, it predicts each feature in turn. It’s done stress, then heart rate, and the next one is movement.
That describes one iteration. It will then repeat the last three steps, predicting stress, then heart rate, then movement. Then it will repeat them again, as many times as you like.
If we do this using IterativeImputer from scikit-learn, we get a scatter plot like this:
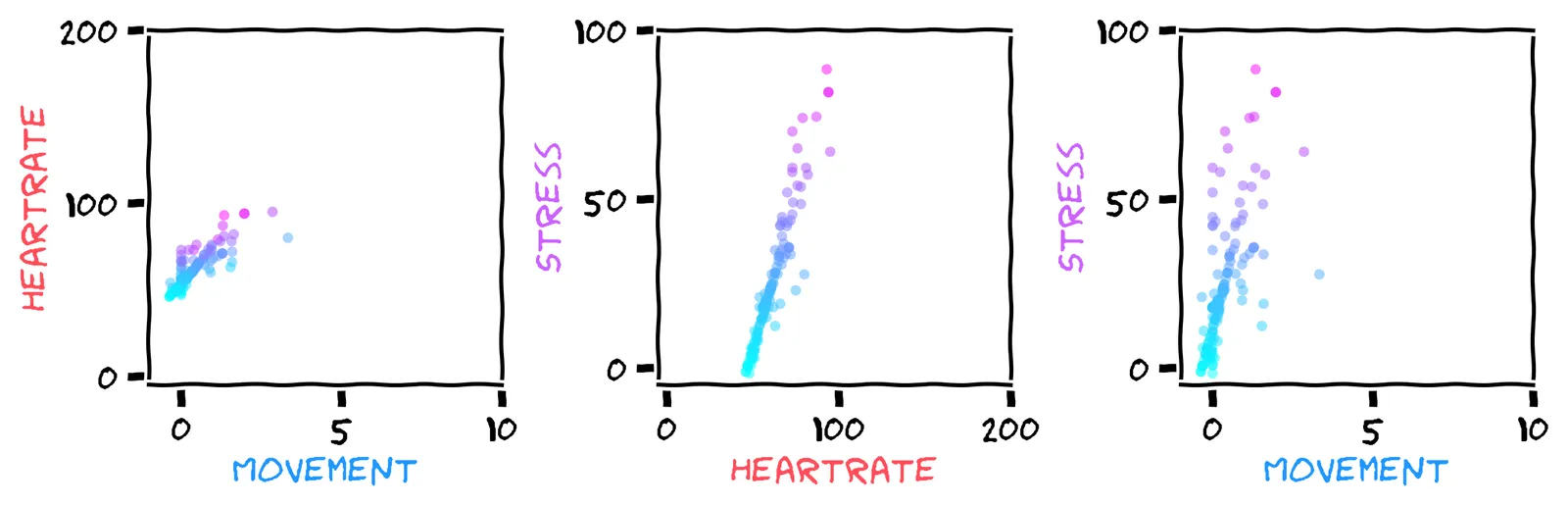
Looking great! We now have the best of both worlds! By using imputation, we can use our entire dataset for training, and by using iterative imputation, it still respects the relationships between features.
So have a guess — will this perform better or worse than listwise deletion?
That was my guess, too!
You have better intuition than me! I would have guessed it would perform better.
But when we run mean-squared error on our test set, we get 67. Dang! It’s still significantly worse than just listwise-deleting most of our dataset!
Here’s what I believe is going on ... Look at the last scatter plot between stress and movement. Earlier, our scatter plots suggested a weak relationship between stress and movement. But iterative imputation has hallucinated a strong relationship. Then our linear regression model uses this false relationship for prediction. Perhaps it would be better off just ignoring it ...
Feature deletion
Let’s rethink our initial problem. In data science, we’re very used to thinking: more data can never hurt! But when using listwise deletion, adding a new feature can hurt, by reducing the number of data points. And advanced methods like iterative imputation don’t necessarily help, because they suggest relationships that don’t exist.
So what if, instead of deleting data points, we delete features instead? Which feature would you try deleting?
Yeah — it’s relationship to stress seems unclear, so let’s try getting rid of it.
Well, it turns out deleting the heart rate isn’t so bad. But deleting the movement feature turns out much better.
No, stress is what we’re trying to predict! If we delete that, our model has nothing to go on. No, I recommend deleting the movement feature, because its relationship to stress seems unclear.
We’ll predict stress using just the heart rate. No imputation, just listwise deletion of points that are missing stress or heart rate.
As always, have a guess — will this perform better or worse than listwise deletion?
I would have thought so! But Incredibly, this simple model gives us an error of just 32:
Yeah! Incredibly, this simple model gives us an error of just 32:

Conclusion
Imputation, despite being theoretically dodgy, is often a necessary evil: in the worst case, listwise deletion can remove all of your dataset! This is why AutoML systems will often impute by default.
But if you’re using imputation, you should be aware of the problems it can cause: destroyed variances, destroyed correlations, and hallucinated correlations. In this chapter, we explored alternatives to imputation, and got lucky: with careful feature selection, we got a good prediction score with just listwise deletion.
End notes
If you want to play around with these results yourself, here’s the Colab notebook.
In the next chapter, we’ll see the power of vectors: how to embed words and images in space, with the spooky ability to do arithmetic like (king−man)+woman=queen.
This chapter is free this week, but Everyday Data Science is a paid course. The following little section is for course buyers, who also get access to all premium chapters of the course.
💓 Premium section: Heart rate variability!
So far, we’ve seen that heart rate correlates positively with stress. But there’s another way that your heart indicates stress, called heart rate variability (HRV). It measures the variance (or standard deviation) in your heart rate.
This was a preview of chapter 4 of Everyday Data Science. To read all chapters, buy the course for $29. Yours forever.
If your heart rate is more variable, what would you guess that indicates?
Counter-intuitively, it’s a sign of lower stress! Aren’t our bodies bizarre?!
So, considering that heart rate variability predicts stress, which of the following imputations of our heart rate might be better for predicting stress?
Yeah, prediction techniques like mean-fill have the annoying habit of reducing the variability (standard deviation). So, sampling techniques like norm-fill could be better here, because it would try to preserve the variability in the data.
Well, prediction techniques like mean-fill have the annoying habit of reducing the variability (standard deviation). So if we tried to use variability to predict stress, it would suggest that the user is very stressed during times without heart rate data.
So, sampling techniques like norm-fill could be better here, because it would try to preserve the variability in the data.
As it happens, if we use our model and dataset above, sampling doesn’t actually help our prediction. That’s partly because we’re using linear regression, which isn’t smart enough to use the standard deviation. And it’s partly because our data points are hourly summaries, whereas HRV is defined using the gap between every heart beat.
But the principle stands: if your data’s distribution is important, and not just its expected value, then consider thinking about imputation as sampling rather than prediction.
See you next time! 👋