Embeddings
An interactive tutorial
In this chapter, we’ll build a semantic search engine. We’ll use distributional semantics to represent words as embedding vectors. Then we’ll use vector arithmetic to represent all text as vectors. Finally, we’ll use normalization and cosine similarity to compare those embeddings. Along the way, you’ll learn the amazing power of vectors, and even how to calculate spider−eight+six.
Searching the Congo
Ahh, another day working at Congo.com, the world’s largest online marketplace. This morning, your boss is complaining: lots of users’ product searches have no results. Here are some books on the warehouse shelves:
Grease, Axel. The Complete Idiot’s Guide to Auto Repair. 3rd ed.
Shaft, Camilla. Truckin’ Hell: An Intro to Pickup Upkeep. 2019.
Stands, Jack. Truckers’ Secret Handbook. Revised ed.
...
And yet, if you search for “beginner truck maintenance” – nada. As the resident data scientist, you’ve been tasked with fixing the problem. Here’s the current search algorithm:
query_words = query.lower().split()
def is_match(product):
return all(word in product.description
for word in query_words)
results = list(filter(is_match, products))Why does the search for beginner truck maintenance return no results?
The current search is doing pure keyword search: it demands that the description contains the word maintenance, but what if it instead contains synonyms like repair or upkeep?
We don’t just need a keyword search; we need a semantic search. Which of these would be most useful to build a simple semantic search engine?
Well, kind of. A dictionary shows the definition of each word. If we looked up the word “maintenance”, we might see the definition “keeping something in a working state”. But to find all the other words to search for, we’d have to read through the entire dictionary to find every other word with a similar definition.
No, a more efficient choice is a thesaurus. When we have a word to search for, we can look it up in the thesaurus, then search for all of its synonyms.
Right! When we have a word to search for, we can look it up in the thesaurus, then search for all of its synonyms.
I’m not sure a rhyming dictionary would be useful here. A rhyming dictionary shows words that rhyme, e.g. given “maintenance”, it might list “flatulence” or “sentence”. Rhyming doesn’t correlate with semantic relationship.
No, we need a thesaurus. When we have a word to search for, we can look it up in the thesaurus, then search for all of its synonyms.
Unfortunately, the Merriam-Webster is hopelessly out of date, and Congo.com has books in 1,000+ languages on every conceivable topic. No, to build our semantic search, we first need to build our own thesaurus.
Distributional semantics
Indeed, it seems hard to get a computer to measure the meaning of a given word. But perhaps we can instead get the computer to measure whether two given words have similar meaning.
Let’s play a game. I’ve picked two secret words W1 and W2. Your job is to guess whether W1 and W2 have the same meaning. To help make your guess, you can choose just one of the following clues:
Well ... okay, the length of W1 is 5 characters, and the length of W2 is also 5 characters. But I suspect this clue doesn’t help you much. I think the most useful clue is the common words that follow W1 and W2.
Okay, that sounds useful!
Well ... okay, W1 is 0.002757% of all words, and W2 is 0.008093% of all words. But I suspect this clue doesn’t help you much. I think the most useful clue is the common words that follow W1 and W2.
Well ... okay, the first two letters of W1 are be, and the first two letters of W2 are st. But I suspect this clue doesn’t help you much. I think the most useful clue is the common words that follow W1 and W2.
To see how this works, we’ll work with this 1GB sample of text from Wikipedia. Data scientists call big collections like this a corpus. In this corpus:
Ten words that often follow W1 are again, airing, construction, operation, play, playing, production, until, work, and working.
Ten words that often follow W2 are again, date, off, out, playing, point, program, until, up, and working.
Now, do you think W1 and W2 are close in meaning?
Good guess. The words were W1 = begin and W2 = start. I’d say they’re close in meaning! And this is why they share four following-words.
The words were W1 = begin and W2 = start. I’d say begin and start are close in meaning. And this is why they share these four following-words: again, playing, until, and working.
It seems reasonable to say: if two words are close in meaning, it causes them to have similar following-words. But does this work in reverse? If two words have similar context-words, does that cause them to be close in meaning?
Here’s a thought experiment. Suppose you start a new job. Your co-workers keep using the strange word grond. “Work gronds at 9am. When it finishes, we’ll grond partying.” Over time, you discover that the word grondhas exactly the same distribution of context-words as the word start. Does this mean the word grond means the same as the word start?
Then you agree with what’s called the distributional hypothesis. This hypothesis says that “a word is characterized by the company it keeps.”
Interesting! Then you disagree with what’s called the distributional hypothesis. This hypothesis says that “a word is characterized by the company it keeps.”
There’s evidence that children acquire much of their vocabulary using this method. According to the distributional hypothesis, the list of words surrounding begin is a sort of “fingerprint” of the word begin. A fingerprint that the computer can measure, and perhaps acquire language like children do!
What does the fingerprint measure?
Let’s see how far the distributional hypothesis goes, by playing the word-guessing game once more. I’ve got two new words, W3 and W4.
Ten words often following W3 are 1960s, 1970s, 1980s, 1990s, 19th, 2000s, 20th, days, medieval, and years.
Ten words often following W4 are 18th, 1940s, 1950s, 1960s, 1970s, 1980s, 1990s, 19th, cretaceous, and night.
Do you think W3 and W4 are close in meaning?
The words were W3 = early and W4 = late. Would you still say these are close in meaning?
Yes, in a sense, the words early and late are close in meaning! They are antonyms.
Really, it depends on what we mean by “close”. The words early and late are antonyms.
The words were W3 = early and W4 = late. They are antonyms.
We commonly say antonyms are “opposite in meaning”. Yet they share many concepts, and therefore have similar word-contexts. For example, the words early and late share concepts like time, comparisons, and events, and therefore include similar following-words, like 1960s.
So our “word fingerprint” idea is not doomed. It’s just that these fingerprints don’t quite measure synonymousness. They instead measure something more like number of shared concepts. But that’s exactly what we want for our task of finding relevant sentences in a long product description!
Word fingerprints are lists of numbers
To build our thesaurus, we’ll first take our big Wikipedia text corpus, and count up which words follow each other. We end up with a big table like this:
We’ve considered the most frequent 10000 words in the corpus. The table above is a sample from that giant table. It shows four current words, truck, car, build, and manufacture, and two following words, the and is. How many times in the corpus is the word truck followed by the word is?
No, truck is followed by is 70 times. It’s followed by the 86 times.
It’s shown in the top-right corner. Look for the cell where truck is on its left, and is above it. truck is followed by is 70 times.
Above, we said that a word’s “fingerprint” is a list of words that commonly follow it. In the full table, how big is one word’s fingerprint?
The full table has 10000 columns, so a single word fingerprint is actually be a list of 10000 numbers: one for each possible word that follows it.
No, a single word fingerprint will be a list of 10000 numbers: one for each possible word that follows it.
That’s pretty big! To keep things manageable for now, let’s just consider two of those following-words, the and is. What is the word fingerprint of the word truck?
No, the word fingerprint of truck is [86, 70]. It’s followed by the 86 times, and is 70 times. The fingerprint [86, 435, 759, 115] describes the previous-words of the word the. We won’t consider those fingerprints here.
Vectors are points in space 🪐
Suppose we’re searching in a document for words related to truck. Use your intuition: which of the following words is most related to the word truck?
Yes, that seems pretty close in shared concepts.
Interesting. I’d say the word car is most related. If I search for the word truck, I’d want to see results with car before results with the word build.
Interesting. I’d say the word car is most related. If I search for the word truck, I’d want to see results with car before results with the word manufacture.
Let’s see if we can measure that. How could we measure how related any two words are, as a number?
First, some terminology. A vector is a list of numbers. A word fingerprint like [86, 70] is an example of a vector. When we use the word “vector”, it’s usually because we’re visualizing the number-list as the coordinates of a point in space. For example, we can visualize our word fingerprints as points in a 2D space:
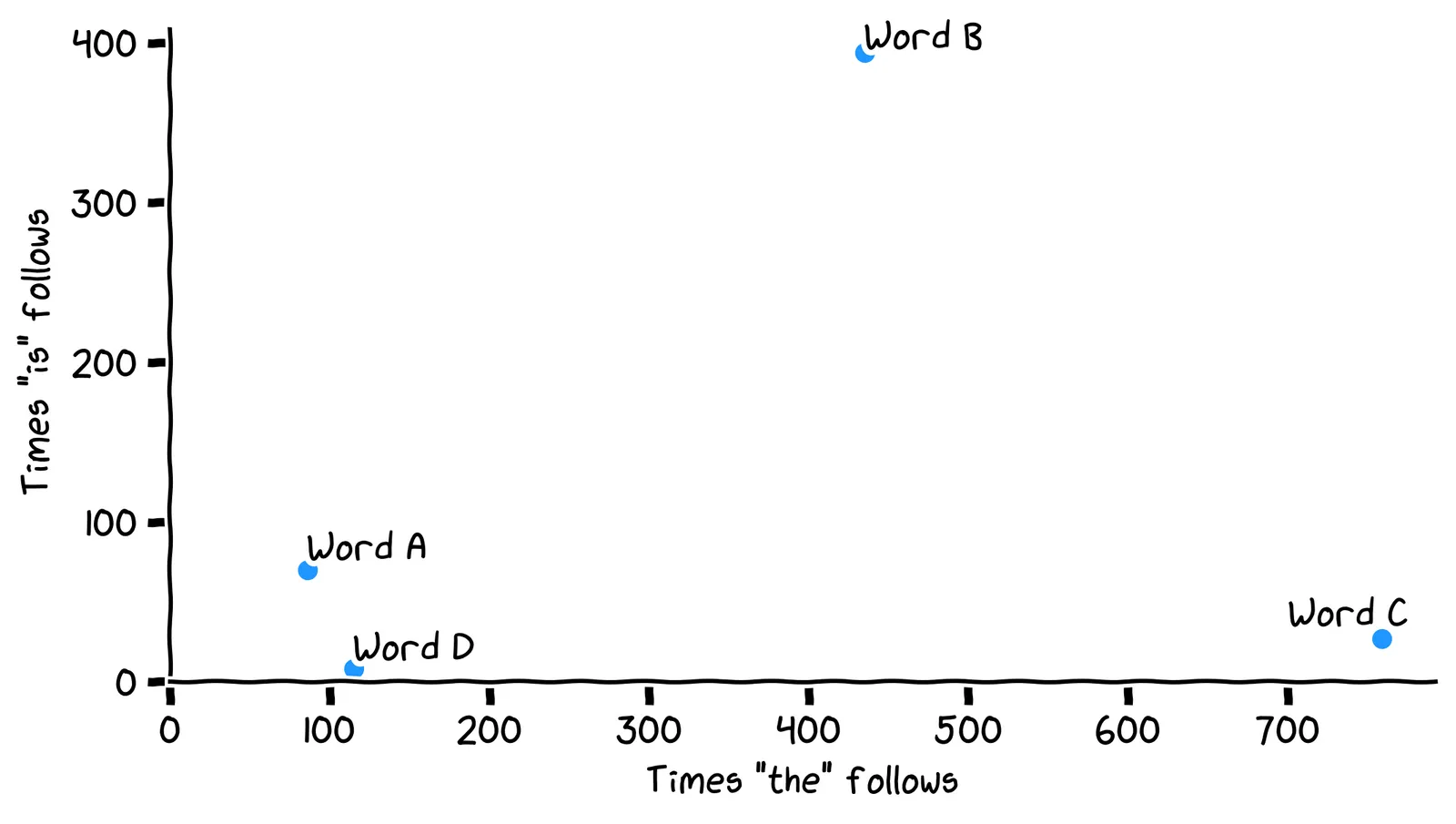
These words are embedded in a 2D space. For this reason, word vectors are usually called embeddings.
Consider embedding C in the plot. Which word does C represent?
No, it’s the word build, which has vector [759, 27], and so is plotted at x=759 and y=27.
No, it’s the word build, which has vector [759, 27], and so is plotted at x=759 and y=27.
Right, it’s the word build, which has vector [759, 27], and so is plotted at x=759 and y=27.
No, it’s the word build, which has vector [759, 27], and so is plotted at x=759 and y=27.
Euclidean distance 📐
A key value of thinking about points in space instead of lists of numbers is that we can intuitively measure distances between points. Here’s Euclid’s formula for measuring the distance between two points in 2D space:
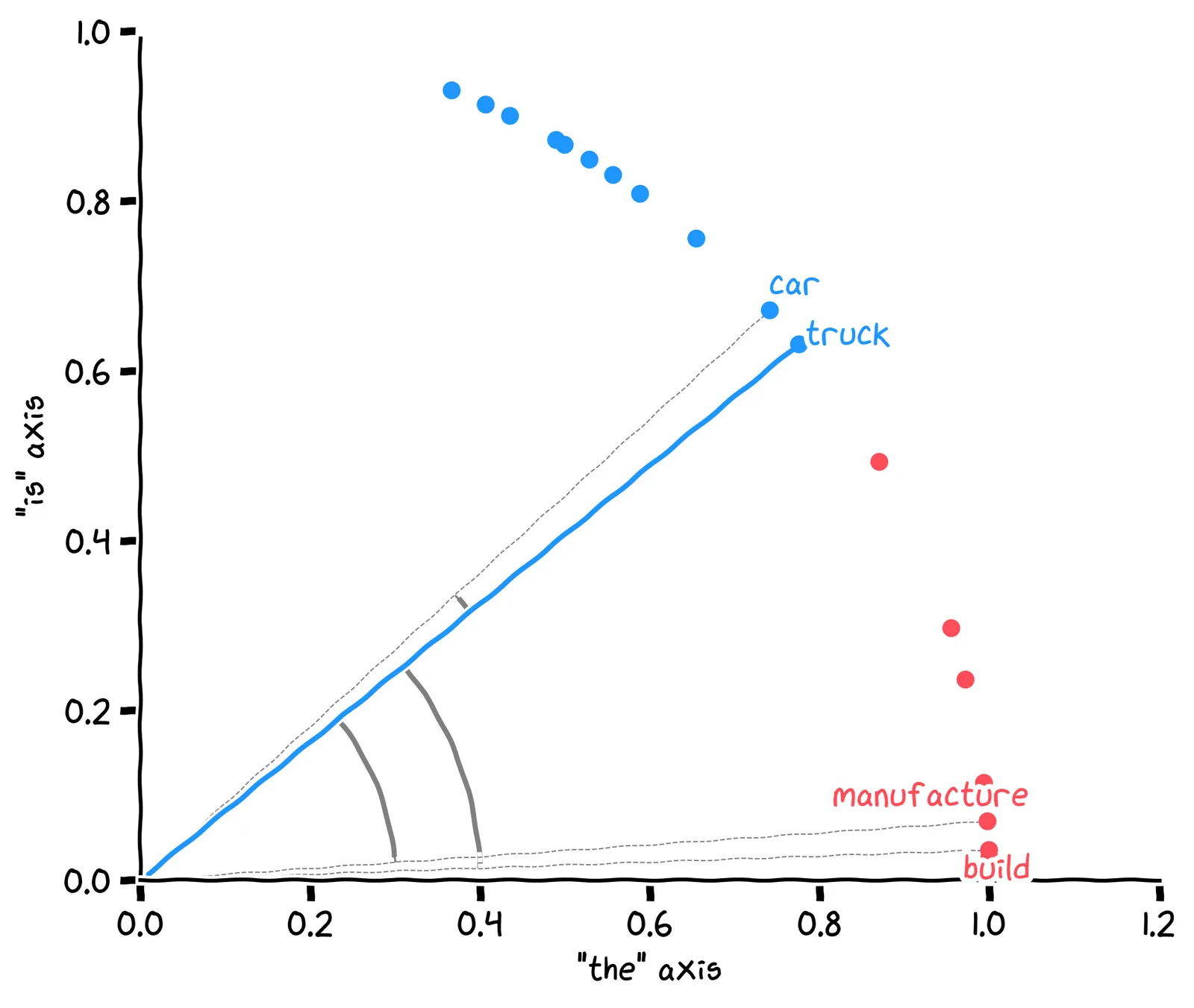
We can use the Euclidean distance formula to find the word with the closest embedding to truck. We’re effectively measuring the lengths of these lines:
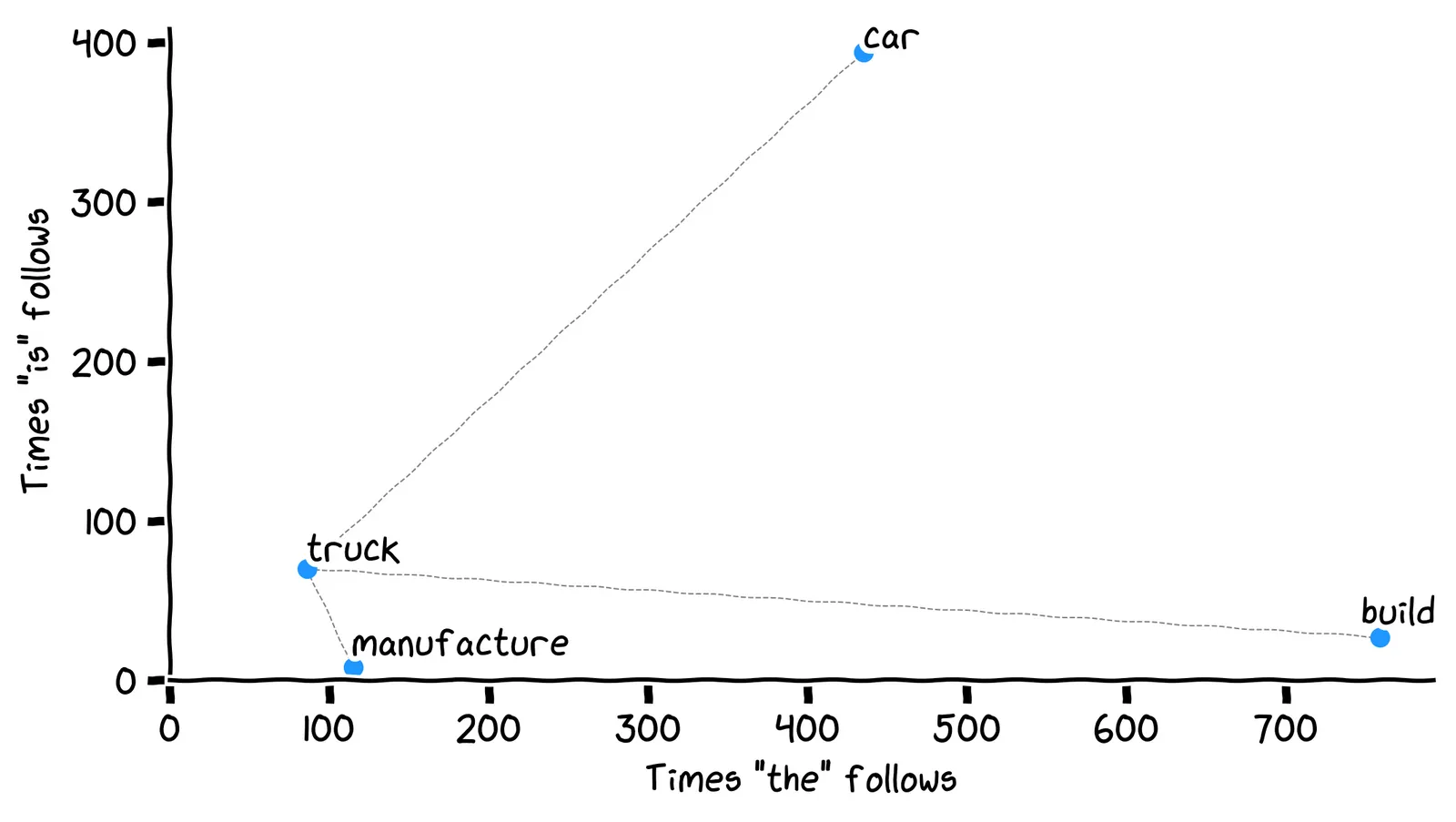
Using this formula, which word embedding is closest to the word truck?
That might be what we want, but by the formula, the closest word is actually manufacture! Look at the lengths of the dotted lines.
No, by the formula, the closest word is actually manufacture. Look at the lengths of the dotted lines.
Right! That’s odd, isn’t it?
Earlier, we said the closest word to truck should be car. But our distance formula says the closest word embedding is manufacture. Our algorithm is not aligned with our desires.
To “fix” this, which of the following could we change?
Either of these can work! Later we’ll see a solution that changes how we measure distance. But first, let’s see a solution that changes the points of the words on the plot.
Normalization 🏐
What does our space of the vs. is actually represent? Suppose I pick a new word W5, and show you its word vector, [cthe,cis]=[13,123]. What does this vector tell you about the word W5?
Right!
That’s tempting, but our 2D space doesn’t have enough information for us to say that W5 is related to trucks. But the vector [13, 123] can tell us that W5 is a noun, and here’s why.
The number 13 is just the count of the times the followed W5 in the corpus. The vector [13, 123] can actually tell us that W5 is a noun, and here’s why.
The word is commonly follows nouns, as in “the truck is red”. The word the commonly follows verbs, as in “manufacture the truck”. The unknown word is mostly followed by is, so it’s probably a noun. It turns out our plot is mostly a plot of nouns vs. verbs:
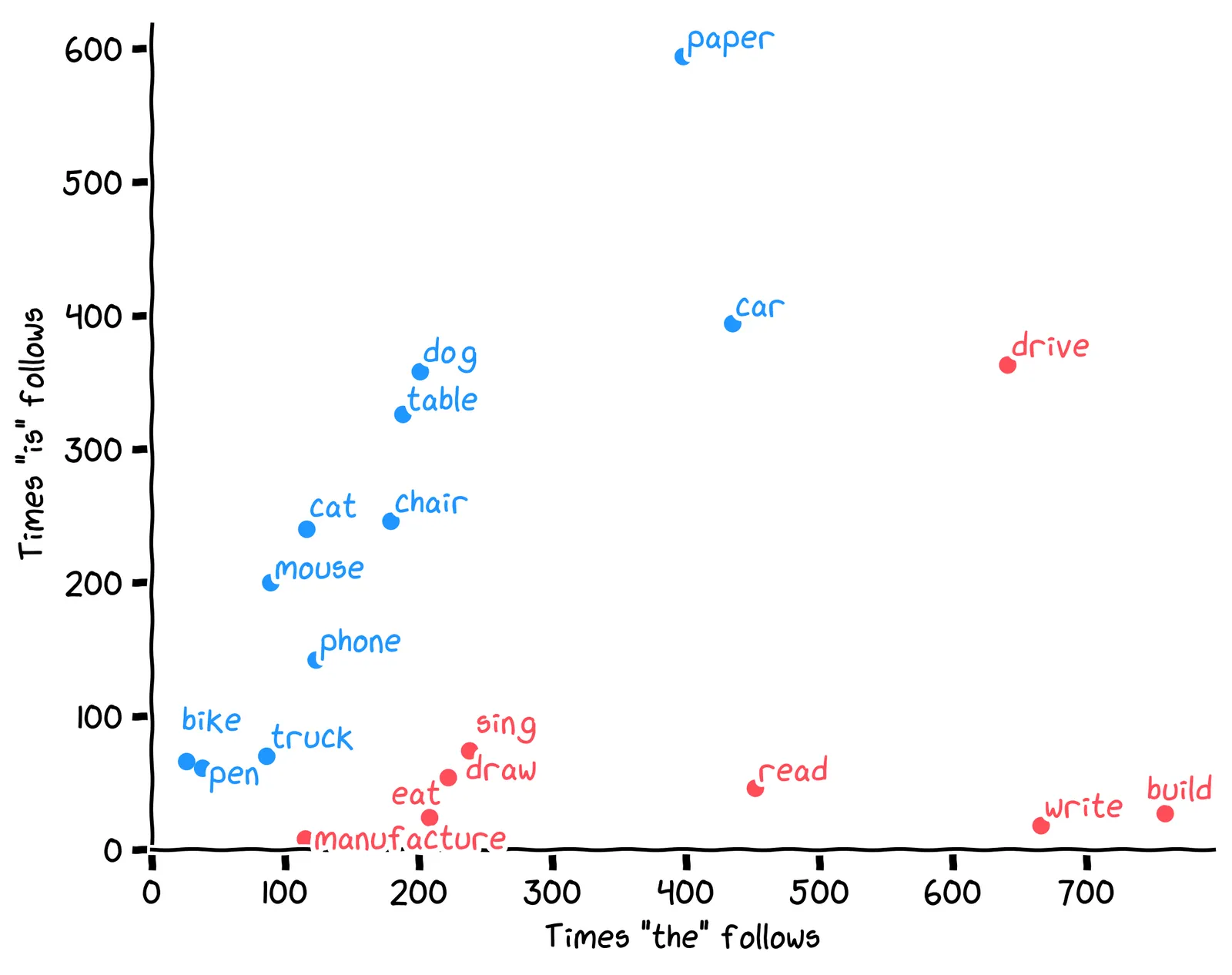
Let’s make this more precise. Say there’s some word embedding [cthe,cis]. Which of the following values would be most helpful to determine whether that word is a noun?
The ratio cthecis is the most helpful. Nouns will have a high value, significantly above 1.0.
That ratio cthecis is the slope of the line from the origin to the point, which we can visualize like this:
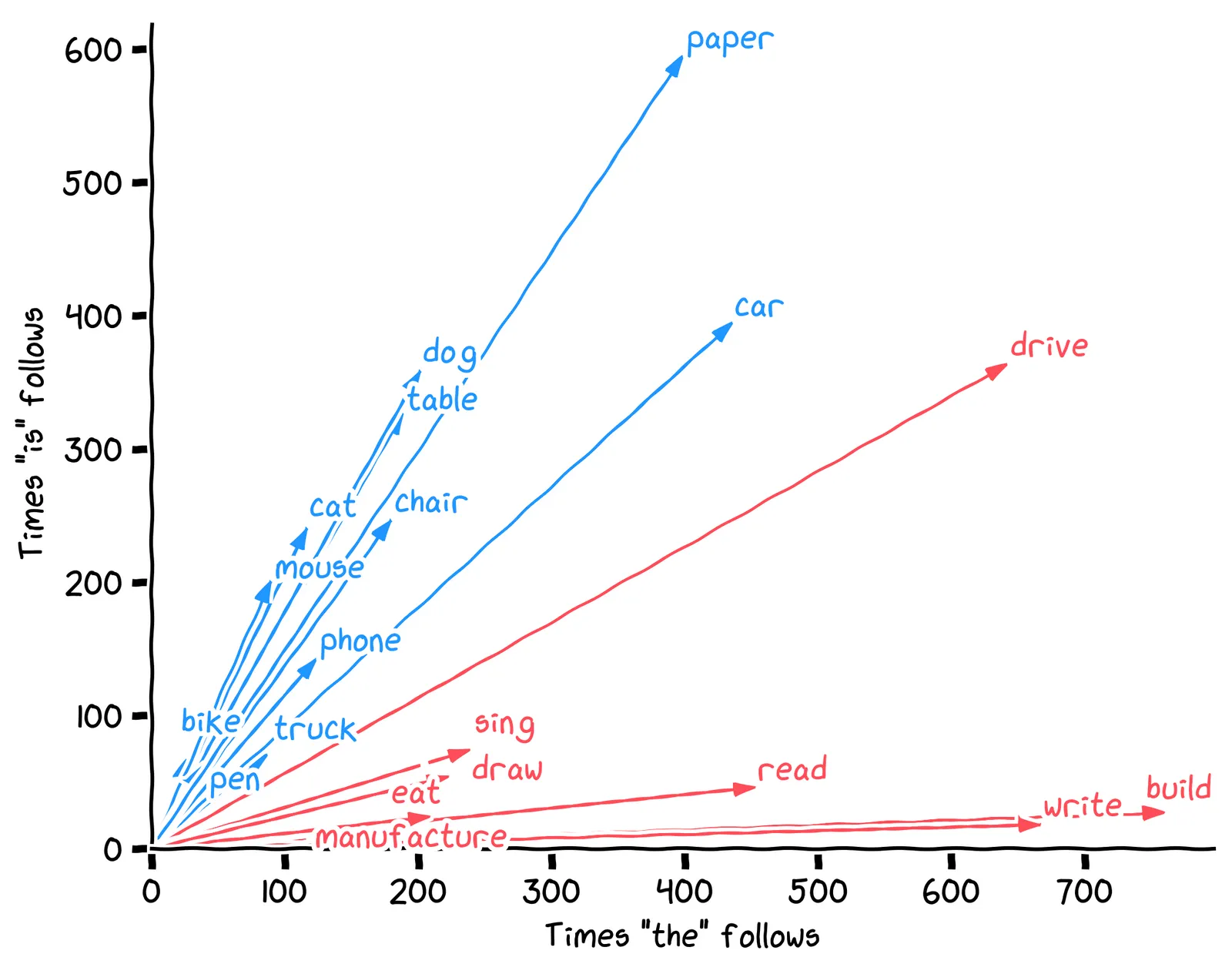
Above, instead of plotting each word as a point, each word is shown as an arrow. This is yet another meaning of the word vector – an arrow that has two things:
A direction: where it “points”.
A magnitude: how long it is.
Given a word vector in our 2D space, the direction of that vector measures the word’s noun-ness. But what does its magnitude measure?
No, the word’s length in characters is not clearly related to the magnitude/length of its word vector. See for example the word car, which is only 3 characters long, but whose vector is pretty long (i.e., has a large magnitude).
The word vector’s magnitude here represents how frequently the word is used.
I’m not sure what “importance” would mean here. No, the word vector’s magnitude here actually represents how frequently the word is used.
Right!
So, when we looked for the closest word to truck, why did we get manufacture rather than car?
No, manufacture and truck have similar frequency. But the word car is much more frequent than either. This is why the word car is far away from the other two.
Right, the words car and truck were pulled away from each other due to their differing usage frequency.
For our purposes, we don’t care about word usage frequency. One way we can fix this is to set all magnitudes to 1. This is called normalization, and it looks like this:
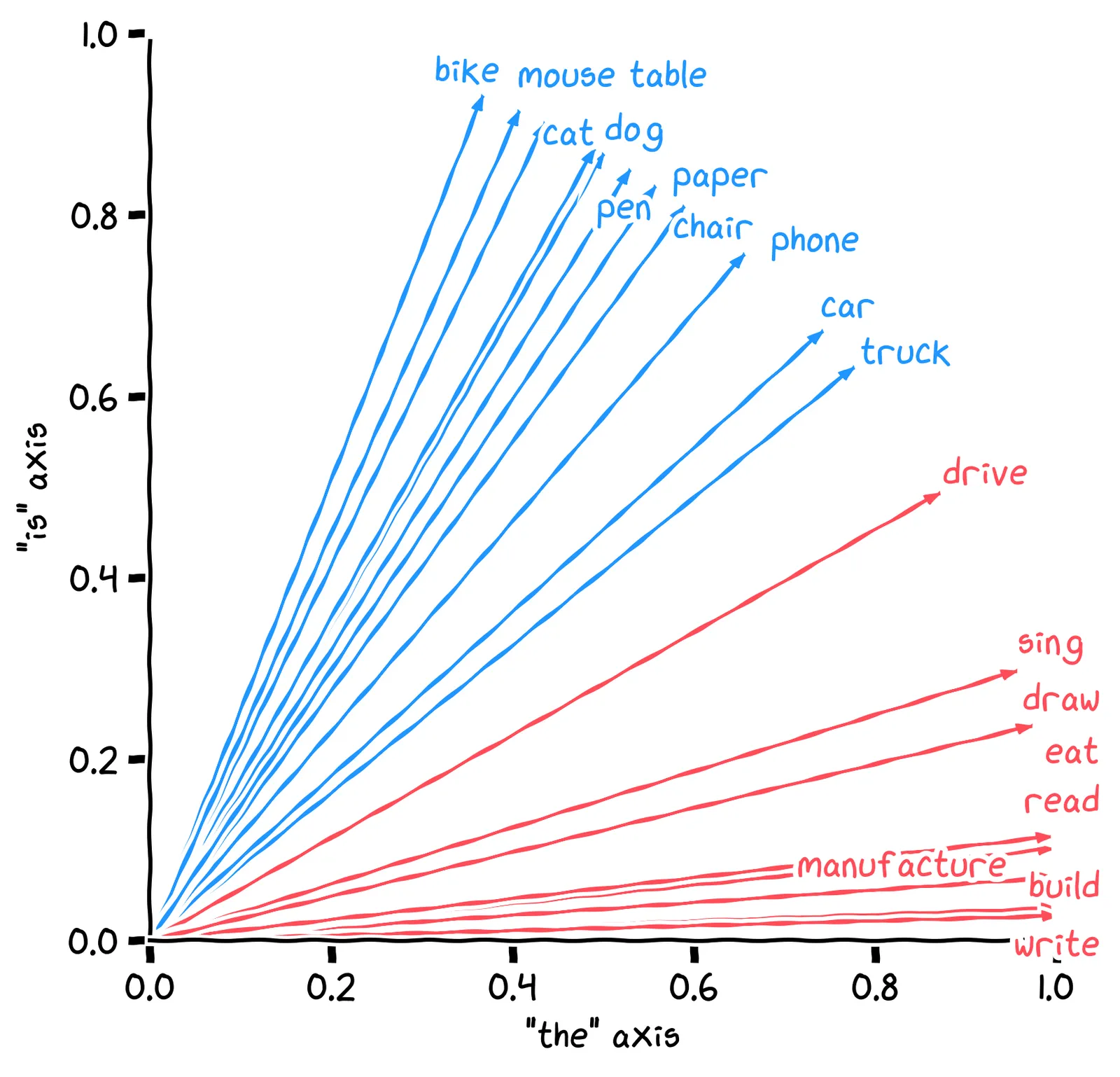
Earlier, when searching words related to truck, the Euclidean distance gave us the word manufacture. After we’ve normalized the vectors, what’s the closest word to truck, using the Euclidean distance?
We’ve made good progress!
Angles 📐
Notice how all the arrow-heads of the normalized vectors lie on the unit circle. There’s a natural way to talk about the position of a point on a circle: the angle. Let’s measure the angle between the word truck and each of the other words.
Which word has the closest angle to truck?
Earlier, we saw the Euclidean distance. We’ve found a different kind of distance: interpret the points as vectors, then take the angle between them. This is called the angular distance between two vectors. In our plot of the vs is, what is the largest possible angular distance between two word vectors?
This one is tricky! If the vectors could point in any direction, the largest possible angular distance is 180°. But all the values in our word vectors are positive counts, so they all point up and to the right. So the largest possible angular distance is only 90°.
In data science, we don’t often use the angular distance. Instead, we use something called called cosine similarity, written as S(a,b). This is the cosine of the angle between the two vectors.
The cosine similarity between two normalized vectors has a formula that’s easy to calculate, called the dot product:
Suppose the normalized vector for the word phone is p=[0.6,0.8]. What is S(p,p), i.e., the cosine similarity between p and itself? (Hint: cos(0°)=1.)
Right, it’s (0.6)2+(0.8)2=0.36+0.64=1.
It’s actually 1, which we can calculate as:
It’s no coincidence that this is 1. If two vectors point in the same direction, their cosine similarity is 1. If they point in opposite directions, their cosine similarity is −1. And if they are orthogonal, their cosine similarity is 0. Which of the following has the largest value?
The vector for truck points in the same direction as itself, so the cosine similarity is 1. The vector for car points in a slightly different direction, so the cosine similarity is a little less: 0.998.
Word arithmetic 🧮
As a brief interlude, here’s a word puzzle: actor - man + woman ≈ ?
Considered purely as a word puzzle, the answer is actress.
But it turns out that, when we use our full 10,000-dimensional word vector, this crazy arithmetic actually works! When replacing the words with their word vectors, and doing the arithmetic, we get a vector which is very close to the vector for actress.
Specifically, we’re using vector addition, which is defined as:
Try it yourself: what is [−1,2]+[1,3]?
Here’s another: spider - eight + six ≈ ?
Why, it’s ant of course! By the logic of word vectors, an ant is a six-legged spider.
Sentence vectors 🗣
Alright, let’s get back to it. We’d found a way to improve on keyword search: use our word vectors to search for words similar to the query words, then include those in our keyword search.
That’s a valid approach, but let’s go all-in on vectors! You’ve seen that we can encode words as vectors. But, considering our new skill of adding vectors, what else could we encode as vectors?
All of these are possible! You can encode almost anything as a vector! For our purposes, it will be useful to encode sentences and queries. Then we could find the most relevant sentences to our query using the same technology we’ve developed above: cosine similarity between a query vector and a product vector.
But how can we get a vector for a sentence or for the query? One way is just to add together all the word vectors in the sentence. Consider the following two sentences:
S1: These terms will be modified frequently without notice.
S2: Notice modified terms will be frequently without these.Will these sentences get different sentence vectors?
Because addition is commutative, these sentences will get the same sentence vector. Despite this naïve approach, addition can give us a useful summary of a text! Using this technique, we end up with this search engine algorithm:
word_vectors = {
"truck": [86, 70, ..., 42], # 10,000 dimensions
"car": [92, 65, ..., 38], # 10,000 dimensions
# ... 9,997 more words ...
}
def embed(sentence):
words = sentence.lower().split()
word_vectors = [word_vectors[w] for w in words]
return sum(word_vectors)
query_vector = embed(query)
def product_rank(product):
product_vector = embed(product.description)
return cosine_similarity(query_vector, product_vector)
results = sorted(products, key=product_rank)Wrapping up
In this chapter, we built a semantic search engine. Our goal was to find products that are most similar to a query string. We did that by converting all the text to vectors, called embeddings. To find word embeddings, we started with a large corpus, and characterized each word by the distribution of words that follow it. To find embeddings for queries and products, we just added up all their word vectors. To compare those vectors, we settled on normalization plus cosine similarity.
End-notes
The approach we took here is called word2vec. It’s a classic algorithm for getting word vectors.
To build the vector for a word, we considered just the immediately following words in the corpus. But word2vec considers more “context words”. For example, the two words after the current word, and the two words before it.
We built word vectors with 10,000 dimensions. Real word embeddings are typically smaller, perhaps ~300 dimensions. This can be achieved by dimensionality reduction. word2vec uses a neural network for this, although there are many other methods.
To get sentence embeddings, we just added up the words’ embeddings. This doesn’t allow words to change their meaning based on context. We could have used an “attention” mechanism for this.
Next in Everyday Data Science:
An Everyday Look At Synthetic Data 🆕
Or, Grow Your Own
The word ‘data’ derives from the Latin for ‘something given to you’. But what if you don’t have friends to give you data for your birthday? Why, you can just create some new data yourself, of course!
In this chapter, we’ll use simulation to train a model without ever dirtying our hands in the real world. It’s just like the Construct in The Matrix.